We have re-implemented in DeLFT (our Deep Learning Keras framework for text processing) the main neural architectures for Named Entity Recognition (NER) of the last two years in order to perform a reproducibility analysis. It appears that:
- although routinely compared in publications, most of the reported results are not directly comparable because they were obtained with different evaluation criteria,
- claims on architecture performance are usually not very well-founded, in fact, the difference in accuracy comes more significantly from different evaluation criteria and hyper-parameter tuning,
- ELMo contextual embeddings are a real breakthrough for NER, boosting performances by 2.0 points in f-score on the CoNLL 2003 NER corpus, but at the cost of a 25-times slower prediction time.
Thanks to some optimisations and parameter tuning, most of our re-implementations outperform the original systems, in particular the recent best performing one (Peters and al., 2018) has been improved from f-score 92.22 to 92.47 with similar evaluation criteria on the CoNLL 2003 NER corpus.
This work is licensed under a Creative Commons Attribution-Noncommercial 3.0 United States License.
DeLFT
Our recently born DeLFT (Deep Learning Framework for Text) is a Keras framework for text processing, covering sequence labelling (e.g. named entity tagging) and text classification (e.g. comment classification). Our objective with this library is to re-implement standard state-of-the-art Deep Learning architectures for text processing having in mind the constraints of production environments, so efficiency, scalability, integration in JVM, etc. which are usually not considered in similar available Open Source projects based on Keras.
Keras offers nice abstractions and independence from Deep Learning back-ends. As we will see in this study, the ease of implementation in Keras does not mean compromise in term of performance. On the contrary, we took advantage of the possibility to very quickly test architectures and hyper-parameter variants. Even if we conceived this exercise as a sleeplessness hobby, we managed to surpass the performances of most of the original systems and we actually got to have some sleep.
DeLFT is Open Source and available on GitHub under an Apache 2 license. All the models presented in this study are included in the distribution. The scope of DeLFT goes beyond simple NER as we actually plan to integrate, in the next months, neural architectures in GROBID and entity-fishing. GROBID is our Java tool for extracting and structuring automatically scholar PDFs and entity-fishing is a service for extracting and disambiguating Wikidata entities in text and PDFs.
Neural NER
Named-entity recognition (NER) is a very traditional (and useful!) subtask of NLP, aiming at identifying Named Entities in text and classifying them into a set of predefined classes such as persons, locations, organisations, dates, etc. In practice, there is no real strict and sound definition on what are Named Entities (in contrast to vulgus entities) nor on what should be these classes, except that these entities cannot be enumerated in advanced (although it is the case for countries) and that the classes are general classes “of interest” (“interest” which, of course, can differ a lot from biologists to journalists).
Manual rules for NER can reach good performance, but they are very costly to write and maintain, and are considered poorly portable from one domain to another. This explains why the efforts on NER are largely dominated by Machine Learning techniques since the beginning of this millennium. Graphical models, in particular Linear CRF, was the state of the art until some recent results with neural NER.
Senna (Collobert and al., 2011) was the first neural DL system to achieve competitive results for NER (89.59 f-score on CoNLL 2003). During the two last years, the following systems have topped the evaluations, and we have re-implemented them in DeLFT:
- BidLSTM-CRF with words and characters input following (Lample and al., 2016)
- BidLSTM-CNN with words, characters and custom casing features input, following (Chiu & Nichols, 2016)
- BidLSTM-CNN-CRF with words, characters and custom casing features input following (Ma and Hovy, 2016)
- BidGRU-CRF with words and characters input following (Peters and al., 2017)
- BidLSTM-CRF with ELMo contextualised embeddings, following (Peters and al., 2018), the current state of the art (92.22% F1 on CoNLL2003 NER dataset, averaged over five runs).
For each system, we set first the hyper-parameters following the indications provided in the papers. We then try to modify slightly the hyper-parameters in order to optmise the performance. After some test with different word embeddings, we used GloVe for all implementations.
Note that all our annotation data for sequence labelling follows the IOB2 scheme.
Result overview
All reported scores bellow are f-score for the CoNLL-2003 NER dataset, the most commonly used evaluation dataset for NER in English. We report first the f-score averaged over 10 training runs, and second the best f-score over these 10 training runs. More details about the evaluation criteria in each column are given in the next sections.
As complementary information, the best reported non-neural ML system for NER uses CRF (Tkachenko & Simanovsky, 2012) and reaches 91.02 f-score on CoNLL 2003 (however this is very difficult to reach, our own re-implementation grobid-ner only reached 88.1 despite quite a lot of efforts in feature engineering).
| Architecture | Implementation | GloVe only (avg / best) | GloVe + valid. set (avg / best) | ELMo + GloVe (avg / best) | ELMo + GloVe + valid. set (avg / best) |
|---|---|---|---|---|---|
| BidLSTM-CRF | DeLFT | 90.75 / 91.35 | 91.13 / 91.60 | 92.47 / 92.71 | 92.69 / 93.09 |
| (Lample and al., 2016) | - / 90.94 | ||||
| BidLSTM-CNN-CRF | DeLFT | 90.73 / 91.07 | 91.01 / 91.26 | 92.30 / 92.57 | 92.67 / 93.04 |
| (Ma & Hovy, 2016) | - / 91.21 | ||||
| (Peters & al. 2018) | 92.22** / - | ||||
| BidLSTM-CNN | DeLFT | 89.23 / 89.47 | 89.35 / 89.87 | 91.66 / 92.00 | 92.01 / 92.16 |
| (Chiu & Nichols, 2016) | 90.88***/ - | ||||
| BidGRU-CRF | DeLFT | 90.38 / 90.72 | 90.28 / 90.69 | 92.03 / 92.44 | 92.43 / 92.71 |
| (Peters & al. 2017) | 91.93* / - |
* reported f-score using Senna word embeddings and not GloVe.
** f-score is averaged over 5 training runs.
*** reported f-score with Senna word embeddings (Collobert 50d) averaged over 10 runs, including capitalisation features and not including lexical features. DeLFT implementation of the same architecture includes the capitalisation features too, but uses the more efficient GloVe embeddings.
Published results are not comparable
Our first observation is that the publications are unfortunately always comparing systems directly using reported results obtained with different evaluation settings. These evaluation settings can bias scores by more than 1.0 points in f-score and invalidate both this comparison and the interpretation of results.
The main goal of a deep learning article is to claim victory at the end of the paper. To help to achieve this not-so-flexible objective, Deep Learning approaches tends here to offer a bit too much flexibility with respect to evaluation:
a) Impact of random seeds: best run versus averaged runs
(Reimers & Gurevych, 2017) discussed in details the impact of random seed values on NER accuracy. The Deep Learning neural networks are by nature non-deterministic due to the random seed values and the impact is statically significant:
For two recent systems for NER, we observe an absolute difference of one percentage point F1-score depending on the selected seed value, making these systems perceived either as state-of-the-art or mediocre. (Reimers & Gurevych, 2017)
In addition they emphasize that even by relying on a validation set, it is not possible to know in advanced which training will perform the best on the test set. In other terms, presenting an f-score from a single best training selected a posteriori is taking advantage of a knowledge on the test set and is thus invalid for evaluation.
To obtain stable and reproducible f-scores, it is necessary to average the f-scores obtained by a certain number of trained models, 10 being the usual selected number.
With DeLFT, we observe that, for the same architecture, cherry-picking the best run a posteriori leads to +0.4 to +0.6 f-score, as compared to the averaged scores over 10 runs.
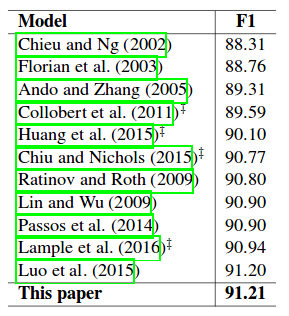
Publish a state of the art or perish.
Excerpt from (Ma & Hovy, 2016)
b) Training with or without the validation set
The CoNLL 2003 NER corpus comes in 3 sets, the training set, a validation set (or development set) to be used for tuning the model parameters and a test set for generating the evaluation metrics. The validation set (17% of the total) is normally not use for training.
However, some recent works like (Chiu & Nichols, 2016) or (Peters and al., 2017) also train with the validation set, leading obviously to a better accuracy. Comparing their scores with previously reported scores that are trained differently is clearly an invalid approach for comparing algorithms. This issue is raised in (Ma & Hovy, 2016).
With DeLFT, we can see that the impact of training with the validation set is between +0.3 and +0.4 on the f-score for the same architecture.
c) Influence of hyper-parameters versus architecture
We observed that as long as the architecture includes a Linear CRF layer as final classifier, the architecture variants (with a CNN of an LSTM for character input, with bidirectional LSTM or bidirectional GRU) has a relatively limited impact on the results.
We see for instance that the best results overall obtained using ELMo are almost identical for BidLSTM-CRF and BidLSTM-CNN-CRF. It is thus easy to twist results at 3 or 4 decimals to put one architecture or another as the best one, but this is of course not significant.
On the other hand, we observed that tuning the hyper-parameters or changing the pre-trained embeddings can have a very significant impact, in the range of 1 to 2 points on the f-score. In general, the more one spends time fine-tuning the hyper-parameters with the validation set, the better the final results will be.
This observation regarding the architecture does however not apply to (Chiu & Nichols, 2016) architecture which does not include a final Linear CRF layer, and whose reported results do not match our re-implementation by a very large margin.
d) (Chiu & Nichols, 2016) not reproducible for us
We were able to reproduce or to slightly improve the originally reported results (when considering the same evaluation criteria) for all the architectures, with the notable exception of (Chiu & Nichols, 2016). The gap is actually important (-1.56 f-score). We used the hyper-parameters as documented in the publication (Table 3) and explored some hyper-parameter variants, but without success to reduce the large difference.
Changing the final softmax layer for a Linear CRF brings an improvement of around +1.5 f-score (something also reported by other works like (Ma and Hovy, 2016)), so we do not understand how it is possible to achieve the reported accuracy with the described final softmax layer only.
e) Only (Peters and al., 2018) presents at the same time a consistent evaluation approach, reproducible results and a reference Open Source implementation
We note that, out of the different re-implemented systems, only (Peters and al., 2018) fulfils a valid evaluation approach by not using the validation set for training and by presenting f-scores averaged over a certain number of training (5, although using 10 would be more standard). In addition, (Peters and al., 2018) is the only including a complete Open Source implementation. However, we also note that their comparison with previous systems mixes f-scores obtained with different evaluation settings.
2018 and ELMo
If we consider the best performing NER system based on CRF, until very recently it was difficult to view neural NER systems as clear improvements for NER in case of relatively small corpus like CoNLL 2003 (averaged f-scores of neural NER not using ELMo are similar to the best reported f-score for CRF). The gain of neural NER was however clear for larger training data like Ontonotes (around +3.0 on the f-score).
In the last months, ELMo contextual embeddings brought a very significant boost in performance. This is also very visible in our reproduced results and it finally confirms the success of Deep Learning Networks for general NLP applications. A similar recent work is the OpenAI transformer also using pre-trained language modeling, but not limited to the sentence and task-independent.
The idea of contextual embeddings is that embeddings are generated dynamically based on the context of several words (the sentence in the case of ELMo) instead of fixed-word embeddings independent from the context (like with word2vec, GloVe, FastText, etc.). ELMo relies on a bidirectional language model applied to a sequence (the sentence) to generate the vector representation of a word.
However, calculating embeddings in context is much more time consuming than simply performing the look-up of a static word embedding. We observed that prediction runtime is strongly impacted by the usage of ELMo embeddings by a factor around 25:
| Architecture | GloVe only (tokens/s) | ELMo + GloVe (tokens/s) |
|---|---|---|
| BidLSTM-CRF | 7068 | 264 |
| BidLSTM-CNN-CRF | 7547 | 272 |
| BidLSTM-CNN | 7143 | 273 |
| BidGRU-CRF | 7752 | 256 |
These runtimes were obtained with a GPU GeForce GTX 1080 Ti on Intel Kabylake i7 (4 Core) 16GB RAM.
So using ELMo is a choice that will depend on the application constraints.
Final words
A reproducibility study is in general a very useful exercise in NLP. This study is here particularly relevant to Deep Learning implementations for NER to draw a line between what constitutes a real stable improvement and what is random effect of experiment or ad-hoc trick with the data.
Hopefully evaluation practices in DL will gain rigour in the coming years. More reliable comparisons in publications will lead to more informative interpretation and analysis about different approaches and architectures, where a gain or a loss can be more trustfully associated to a particular aspect of a system.
Creating a culture of replication is today often pointed as crucial in science. Deep Learning has certainly some advantages for this with a strong culture of Open Source. Using an open dataset encoded in a standard way is very important for reproducibility, but a dataset also needs to be associated with a stable evaluation methodology to achieve a reproducibility purpose over time.
Behind this study, we think also that negative results should be more emphasized as valuable research contributions. The pressure on “best-of-breed” publications encourages researchers, who are constantly under pressure to sustain their career, to take advantage of unclarities in evaluation methodologies which do not serve the long term research progress.
We thank Pedro J. Ortiz, who is working with us at Inria Paris, for testing and contributing to DeLFT on these NER experiments! Opinions and errors are the sole responsibility of the author.
