S4 (Structured and Semantic Search Service) is a generic end-to-end infrastructure to rapidly build and deploy a search service providing state-of-the-art structured and semantic searches in collections of technical and scientific documents. S4 is entirely based on Open Source components. One of the strengths of this system is to automatically enrich documents with our text mining tools, and make these enrichments available for improving search, discoverability and presentation of information.
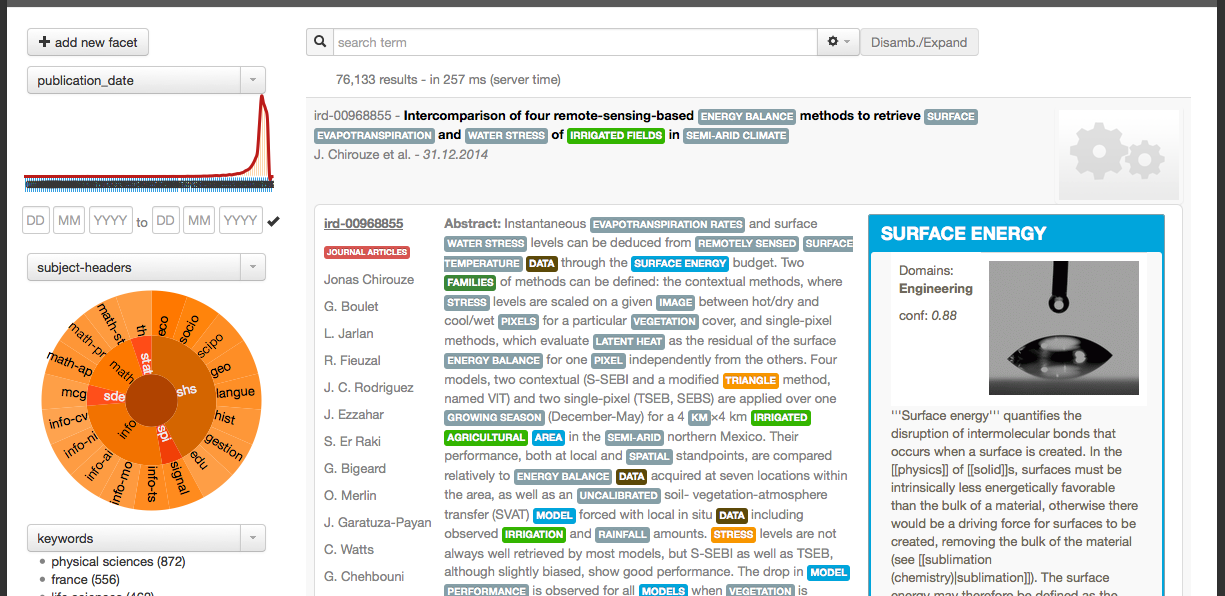
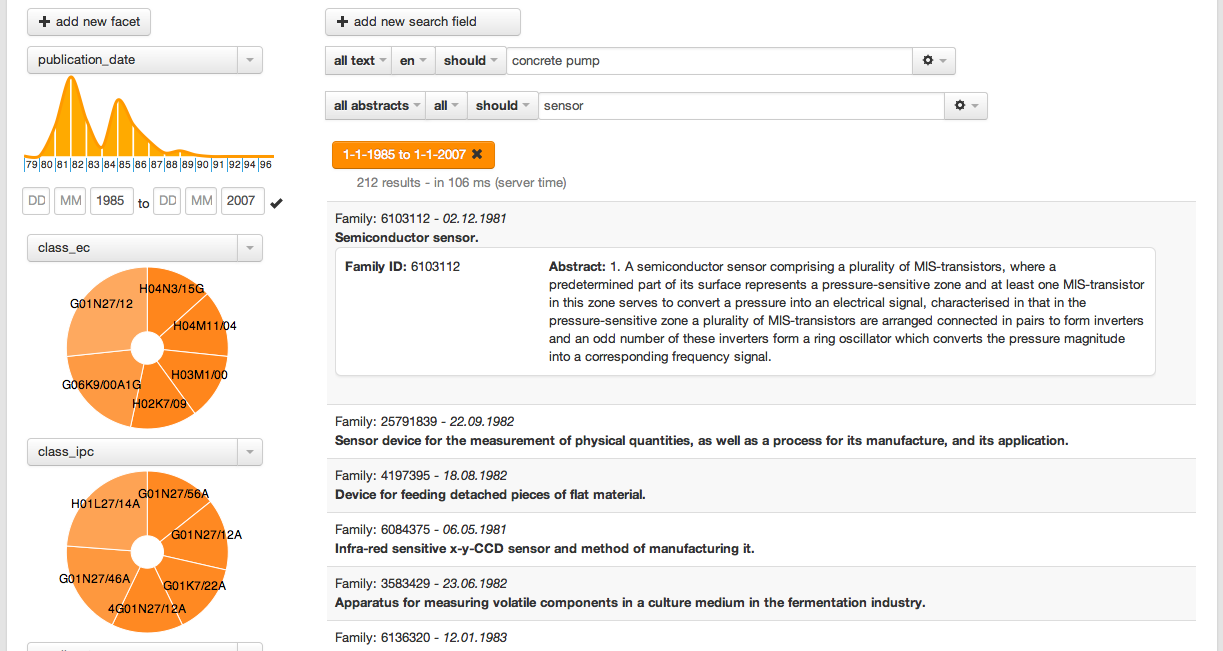
Structured search is the ability to search and facet a collection of documents according not only to the textual content but also to the structure of the documents. For instance, it allows a user to search freely a collection of scientific papers with structure constraints such as search in specific sections (e.g. introduction), in certain bibliographical citations fields, in figure captions or particular annotation subfields.
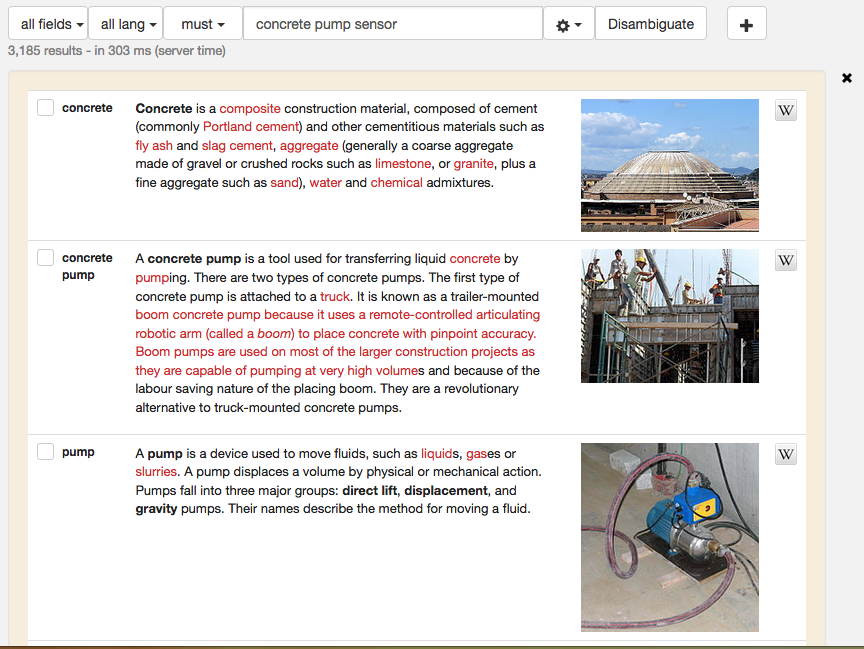
Semantic search refers to the exploitation of sense information for improving the general quality of search. In our case, we offer the possibility to express query as concepts/entities, view semantically annotated documents and a semantic disambiguation of the search query that the user can interactively manipulate.
The final web-based GUI search client is easily parameterizable and offer the full range of modern search functionalities, including statistical faceting against any substructures of the document, filters, possibilities of complex queries, query disambiguation, an optional automatic query completion service, etc.
Several transparent optimization at indexing and request time allow very fast searches, with “search as you type” results refresh (< 200ms) for all functionalities (results, snippets, facets) for collections of several hundred thousand documents. Complex searches remain sub-second in collections of million documents.
End-to-end infrastructure
Ingestion: To offer the full range of modern search functionalities, a collection of documents need first to be ingested (for instance via OAI-PMH) and integrated in a common document model. The common document model of the S4 system is the TEI. For digital library applications, we develop for this purpose GROBID which can automatically transform raw scholar PDF documents into structured TEI. We also use a large set of XSL style sheets to transform publishers native XML documents into TEI called Pub2TEI, covering also patent publications.
Storage and document provision: Documents binaries and TEI are stored into MongoDB, taking advantage of GridFS for scalability and efficiency.
Document enrichment: The documents are automatically enriched with semantic annotations based on our different entity recognition and disambiguation tools. entity-fishing in particular used as the backbone of semantic search, together with other scientific entity recognizers.
Indexing: TEI documents are transformed into canonical JSON documents via JsonML and indexed into ElsaticSearch via custom mappings performing transparently optimization and expansion of the TEI documents into JSON to allow faster queries.
Front-end: We develop a search front-end in Javascript for the S4 service immediately available after the indexation step. Queries are optimized with respect to the indexed TEI structures. The data available at the front-end level follow the same document model as the rest of the architecture for the simplification of the maintenance by avoiding any “silo” effects. The front-end is easily customizable as illustrated bellow.

Query disambiguation relies on entity-fishing to disambiguate user’s query against Wikidata entities. The follow-up can be interactive (the user refining the entities) or transparently for improving the ranking or faceting the result set.