GROBID
If you are a scientist, you may already use GROBID without knowing it. GROBID is the tool used for extracting automatically metadata, citations and structured information from scientific papers in many large scale scientific information service providers, like ResearchGate, Mendeley, CERN, HAL research archive, Internet Archive, CiteSeerX, etc.
Created by the founder of science-miner, GROBID is an Open Source tool for parsing and extracting structured information from technical and scientific documents in raw format like PDF. The large majority of the scholar documents are only available in PDF (more than 90% of the papers prior to 2000) which is not adapted to text mining processing and corpus analysis. Even when a publisher XML format is available, the level of structuring might not be sufficient and uniform, so further processing and harmonization are often necessary.
GROBID has been developed to address these issues in a reliable, fast and scalable manner thanks to machine learning techniques – cascaded sequence labeling models (CRF and RNN). This tool is the first building block of a text mining infrastructure, it is actively maintained and continuously improved.
Metadata extraction
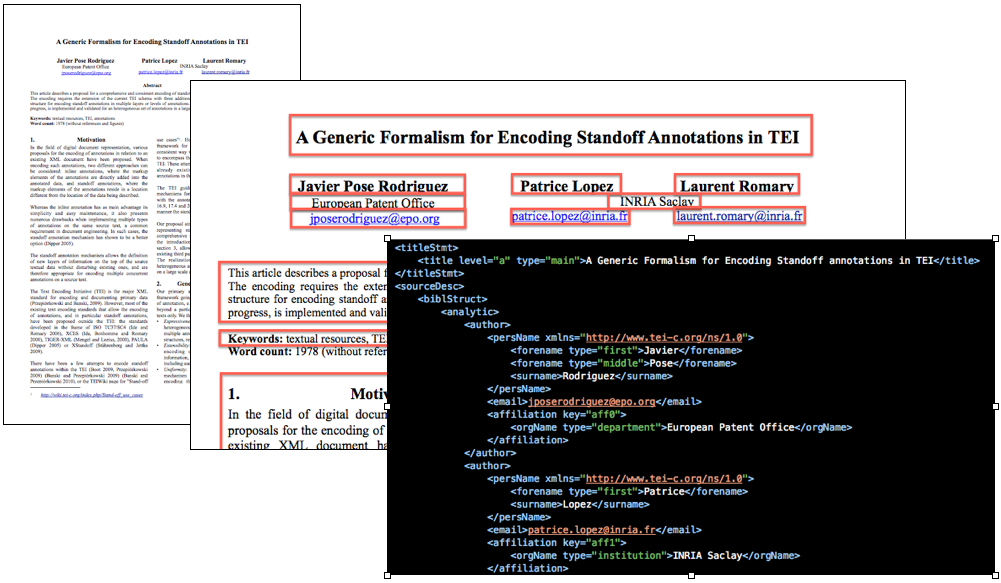
Depending on the publishers/collections, GROBID should be able to extract the metadata (title, authors, affiliations, abstracts, etc.) of a scientific document in PDF with an accuracy between 80-95%, largely in sub-second time.
Structured citation extraction
GROBID extracts bibliographical references with an average accuracy between 70-90% per reference and provides standard bibliographical formats for further integration in a text mining or digital library system.
Document body structuring
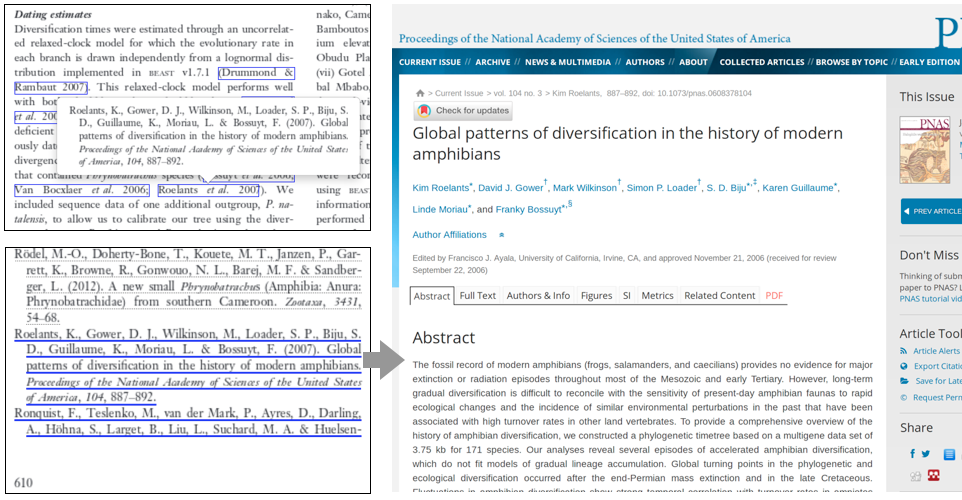
GROBID can extract, normalize and structure the body of a PDF document in XML TEI. The explicit recognitions of paragraphs, section titles, citation call-out and contexts, figures, tables, formula, foot notes, etc. make possible a valid usage of modern text mining techniques.
It is known that Text mining full research articles gave consistently better results than text mining abstracts. However, the team reporting this observation also stressed that the most time-consuming and challenging step in the study was not negotiating permissions with publishers, but converting the full-text articles the publishers provided in the PDF into a machine-readable text format. GROBID is one of the rare tool addressing this bottleneck, providing complete full text structures with state-of-the-art and continuously improving accuracy, in a scalable implementation.
In addition to the Open Source machine learning models for document body structuring, SCIENCE-MINER also provides superior models based on additional manually annotated training data not included in the official GROBID repository.
PDF layout and structure alignment
The structures extracted from GROBID are synchronized with the original PDF layout with coordinates. It makes possible to enrich back the PDF dynamically with clickable, in context, annotations – in particular with browser based visualization without modifying the original PDF.